
前言
在数据库的维护当中对表的垂直才分是必然的,基本上在业务刚开始准守 3NF 是明智的,当然也可以有一些反范式的设计。但是,建议还是应该在3NF的基础上再酌情考虑反范式。
当遇到真的要对一些表进行拆分,那要拆那些字段嘞?下面我们就来分析一下。
场景
在新业务上线后导致TPS突然增高,这时我们对新上的业务又不是很懂。而问题又要分析解决。
分析解决步骤
- 解析近期生成的binlog文件获得是哪个表哪个字段操作的多。
这边使用到了 吴炳锡 大神的一个工具 parsebinlog
该工具可以解析出表的操作情况
链接: https://github.com/wubx/mysql-binlog-statistic
上面工具只能解析单个binlog文件的操作,如果要解析多个文件的可以使用 笔者的工具 pasrebinlog_stat.py
pasrebinlog_stat.py 是对执行parsebinlog解析完之后的数据进行的统计生成excel文件的工具
具体使用方法(在github最后有一点小小的说明):https://github.com/daiguadaidai/mysql-binlog-statistic
使用笔者的方法统计后会生成 5 个文件:
|
1
2
3
4
5
6
|
ll
–rw–rw–r— 1 manager manager 58191 Sep 6 17:18 format.txt
–rw–rw–r— 1 manager manager 100352 Sep 6 17:18 sort_by_delete.xls
–rw–rw–r— 1 manager manager 100352 Sep 6 17:18 sort_by_insert.xls
–rw–rw–r— 1 manager manager 100352 Sep 6 17:18 sort_by_total.xls
–rw–rw–r— 1 manager manager 100352 Sep 6 17:18 sort_by_update.xls
|
如果关心update操作可以查看sort_by_update.xls 其中是按update操作次数降序排列的。
然后根据要了解的 表名 到format.txt中查看哪个字段更新平凡
- 查看解析出的文件相关 excel
如这边我在sort_by_update.xls文件中看到 t1 表在定义行,说明他的总update量最多。
然后在format.txt找到 t1 表的统计格式如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
Table `app_db`.`easy_channel_item`:
Type TOTAL opt: 440353
Type INSERT opt: 8049
Type DELETE opt: 1419
Type UPDATE opt: 430885
28 col : 517
23 col : 145
7 col : 379383
6 col : 46449
12 col : 2
13 col : 2
9 col : 21
8 col : 21
5 col : 4102
4 col : 3853
26 col : 3
27 col : 173
21 col : 136
24 col : 3
25 col : 116
|
从上可以很清楚的看到 ‘6 col’ 和 ‘7 col’操作占用了大多的update操作。
通过查看数据库表结构可以知道这两个字段分表是 price 和 inventory。
- 拆分字段
知道了哪个表的那个字段update频繁,可以先将字段从表中剥离出单独的表。至于需要不要开另外的库需要看会不会对其他主要业务有影响(如:下单付款等)。如果有影响在拆到其他库中。
拆出来的目的主要是为了让每一个page能存储更多的数据,并且不会让 t1 表的数据在缓存中能保存的更长久,不会出现平凡的age out 显现(没有解决TPS高的问题)。
- 对于要提高TPS一般有两种方法
第一种:将TPS分散,也就是需要将表进行分区到不同库(一般这样要考虑的东西太多。数据量不大一般不考虑)
第二种:使用能提供更高TPS的产品(这边建议 redis 是不错的选择)。
这边排除第一种
使用第二种:
更具时间经验值:一般使用redis 能提供 TPS:3-5W 更具机器情况还有所提高。
QPS:7-10W 更具机器情况还有所提高。
对于我们的TPS的情况 3-5W TPS 的redis一般能够胜任
这边主要担心的就是有关 持久化 的问题,这就是架构上需要设计的了。
- redis 自身具有持久化功能,每秒持久化一次。
- 更具我们 同步的情况其实同步可以忍受短时间不实时现象。如果出现redis失效(宕机或怎么的可以重启redis重新同步所有数据)
- 可以搭建 redis的master-slave 或 cluster 都行这样就能很好的解决一台redis宕机问题。
- 可以根据 数据库软件设计的某些原理和借鉴秒杀架构,在后台不定期的将redis的数据同步到MySQL。
步骤可以有:
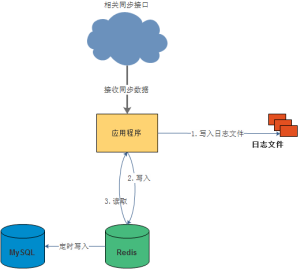
- 先将相关数据 格式化 的写入到日志文件(有能力提供消息队列更好)。
- 写入日志成功之后再将数据在redis做操作。确保出问题有数据库可查。
最终配合redis的架构图:
文章转载来自:ttlsa.com
