
Riak 是什么
Riak 是一个 erlang 开发的开源的分布式 key-value 数据库,
在 High Availability, Fault Tolerance, Scalability 方面表现优异。
其实现受 Amazon Dynamodb 启发,是一个很有代表性的分布式数据库。
Riak 集群是一个去中心化的集群。每个服务器节点都是平等的,可以自由地添加和删除。
这使得 Riak 的故障转移(Failure Over)和扩展非常容易。
在 CAP 理论方面,Riak 可以自由地在 CP 和 AP 之间做平衡。
理解 Riak 的分布式数据库模型
Riak 的数据冗余
下面还是让我们从简单的例子开始,来理解下 Riak 的分布式数据库模型,包括数据的存储,节点服务器的,CAP理论的关系等。
首先让我们先定义一个概念:N,表示数据的”份数”。在分布式数据库中,一份数据往往会存储多份拷贝(所谓冗余,或者 replications)
现在,假设我们有一个服务器节点(node1),存有三个数据(key分别是 P0, P1, P2),N = 1。那么可以想象,这三个数据都是存放在 node1 中。如下图所示:

当 N = 2 时,假设 P0, P1, P2 的冗余数据分别是 R0, R1, R2, 那么可以想象,这6个数据也应该都存储在 node1 中,如 下图所示:

这时候,让我们把服务器节点增加到2个(node1, node2),那么可以想象,6个数据有很多中组合方式,例如下面这两种:


也许你发现了,他们有个共同点:同一个数据的冗余数据放在不同的服务器节点中。这样就算一个节点删除(当机)了,集群的数据仍然能保证完整性。
这为故障转移(Failure over)提供了基础。
那么现在的问题来了,是否有什么科学(公式化)的方式来找到分配这些数据的组合(之一)呢?
Riak Ring
Riak 通过被称作 Riak Ring 的东西来解决这个问题。
首先,Riak 将所有的 key 通过 hash 函数映射到一个 160 bit 的整数空间中。
即一个 key 对应着一个 0 ~ 2^160 – 1 的整数。
然后,Riak 引入了 vnode(虚拟节点) 的概念,vnode 个数是可以配置的,默认是 64。
160 bit 的整数会均匀的分布到所有的 vnode。
最后,这些 vnode 会”均匀地”分配到 物理节点上。具体的分配的方法很巧妙,通过 Riak Ring 这样的东西。
下面我们用一幅图来具体解释下 Riak Ring。图中,假设 vnode 32 个,服务器节点 4个。
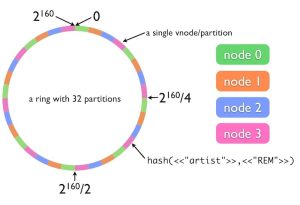
让我们把 160 bit 想像成一个环,环上的一小段代表一个 vnode。四种颜色分别代表 4 个服务器节点。
2^160 个整数按照从小到大的顺序均匀地分布到 32 个 vnode 中,例如 2^159 是第 17 个 vnode 上的第一个整数。
32 个 vnode 按照从小到大的顺序依次被分配到 4 个服务器节点上。即:
- 1, 5, 9…29 vnode 分配给第1个服务器节点(node1)
- 2, 6, 10…30 vnode 分配给第1个服务器节点(node2)
- 3, 7, 11…31 vnode 分配给第1个服务器节点(node3)
- 4, 8, 12…32 vnode 分配给第1个服务器节点(node4)
现在还剩下一个问题:
冗余数据的存储
我们先假设 N = 3(即有2份冗余存储)
假设要存储的数据,key 为 test-key ,根据 Riak Ring 算出来,应该存储在 vnode6(即:node2)上。
那么 拷贝1 存储在 vnode7(即:node3)上,拷贝2 存储在 vnode8(即:node4)上。
所以 Riak 对于冗余数据的存储策略是:将冗余数据依次存到下一个vnode中。
文章转载来自:ttlsa.com
