
在 Riak 这样的分布式key-value数据库中,CAP理论是怎么起作用的。
Nodes/Writes/Reads
首先还是让我们来明确几个概念。
N odes
需要”最终”包含正确的值的服务器节点总数(正确的冗余数据拷贝数)。
W rites
每次写操作,我们需要确保最少有多少节点被更新。也就是说,我们在执行写操作的时候,不需要等待 N 个节点都成功被写入,
而只需要 W 个节点成功写入,这次写操作就返回成功,而其他节点是在后台进行同步。
R eads
每次读操作,我们需要确保最少读到几份冗余数据。也就是说,我们在执行读操作的时候,需要读到 R 个节点的数据才算读成功,否则读取失败。
为什么要这三个变量?其实这三个变量直接关系到了 Riak 的 CAP 特性。下面我们就来一一说明:
Eventual Consistency(W + R <= N)
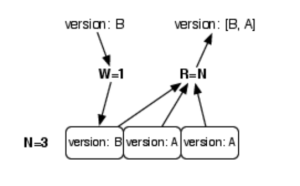
如下图所示:假设我们的 N=3, 设置 W + R <= N(例如:R=2, W=1)。这样我们的系统可以相对保证读写性能。
因为写操作只需要一个节点写入就返回成功。

然而这里有机率发生这样的情况:就像图中所示,我写入的是node1(versionB),然后进行了一次读操作。
恰好这时候新数据尚未同步到node2, node3,而读操作又是从node2,node3取的值。由于这两个节点的值都是 version A,
所以得到的值便是 version A。
不过随着时间的推移,node1 中的 versionB 会被同步到 node2 以及 node3 中。
这时候,再有读操作,得到的值便是最新值(versionB)了。
这就是所谓的 Eventual Consistency。整个系统有着较高的读写性能,但一致性有所牺牲。
如果我们需要加强一致性,可以通过调整 W, R, N 来实现。
接下来我们会讨论如何调整 W,R,N 的关系来平衡读写性能和一致性(即 A 和 C 的平衡)。
通过调节 W,R,N 的关系来调节一致性和读写性能的关系
一种极端做法(下图所示),我们可以设 W=N, R=1。其实这就是关系型数据库的做法。
通过确保每次写操作时,所有相关节点都被成功写入,来确保一致性。这样可以保证一致性,但是牺牲了写操作的性能。

还有一种极端做法,我们可以设W=1, R=N。这样,无论你向哪个node写入了数据,都会被读到。
然后你读到的N个值也可能包含旧的值,只要有办法分辨出哪个是最新的值就可以了
(Riak 是用一直叫向量钟(Vector Clock)的技术来判断的,我们会在后面的博客中做介绍)
这样可以保证一致性,但是牺牲了读操作的性能。
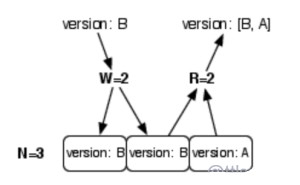
最后再给出一种被称作 quorum 的做法。如下图所示,可以设置 W + R > N (例如 W=2, R=2)。这样同样可以保证一致性。
然而性能的损失由写操作和读操作共同承担。这种做法叫做 quorum。
文章转载来自:ttlsa.com
